출처 : https://if.kakao.com/session/22
if(kakao)2021
함께 나아가는 더 나은 세상
if.kakao.com

리뷰 포인트
- 스마트 메시지 서비스 소개
- 스마트 메시지 서비스 설계
- 스마트 메시지 서비스를 설계, 개발하면서 고민한 문제들과 해결 사례
- kafka streams 기술 소개
- kafka streams 적용 과정
스마트 메시지 서비스 소개
"스마트 메시지 서비스는 카카오톡 채널 광고 메시지의 일종입니다." 라는 말을 듣고 생각에 빠졌다. '카카오톡 채널 광고 메시지? 그게 뭐지?' 카카오톡 채널은 광고를 위해 만들어진 계정이라고 보면된다. 우리가 어떤 채널을 추가(구독)하면 그 채널로 부터 광고 메시지를 받을 수 있다. 필자는 광고를 선호하지 않아서 채널 서비스는 사용하지 않는다. 스마트 메시지 서비는 이 채널 서비스의 광고 메시지에 소재최적화 기술과 유저타게팅 기술을 적용하여 효율적으로 광고 메시지를 보내주는 서비스다.
소재최적화 기술은 광고주가 여러 가지 광고 시안(소재)을 만든다. 예를 들어 사과를 광고하기 위해 다음과 같은 두 가지 소재가 나올 수 있다. "정말 맛있는 꿀 사과", "피부에 좋은 사과"이 두 가지 광고 메시지(=광고 시안 = 소재)가 있을 때 가장 반응률이 높은 소재를 계산하여 광고 메시지로 선택하는 기술이다. 이 때 사과를 좋아하는 A라는 유저에게는 "정말 맛있는 꿀 사과"라는 광고 메시지가 전송되고 피부에 관심이 많은 B라는 유저에게는 "피부에 좋은 사과"라는 광고메시지가 전송된다.
유저타게팅 기술은 채널을 구독한 유저들 중 가장 반응률이 높을 것 같은 유저를 계산하고 그 유저에게만 광고 메시지를 보내는 기술이다. 예를 들어 어떤 채널 A에 30만명의 구독자가 있을 때 광고 예산의 제약으로 10만명에게만 메시지를 보낼 수 있다고 한다면 가장 반응률이 좋을 것같은 10만명을 골라서 메시지를 보내주는 기술이다.
스마트 메시지 서비스 설계
위 그림이 스마트 메시지 서비스의 흐름도이다. 이 흐름도를 여러 관점에서 보면 쉽게 이해할 수 있을 것이다.
- 서비스 사용자 관점
서비스 사용자는 크게 광고주(채널)와 채널 구독자가 있다. [1]먼저 광고주는 카카오모먼트 dsp 플랫폼을 통해 [2]자신의 광고 메시지(소재)를 여러 개 등록한다. 이 후 [3,4,5]카카오톡 인공지능이 반응률을 고려하여 광고 메시지(소재)들 중 하나(소재최적화)를 적절한 채널 구독자들에게(유저타겟팅) 전송한다. 이 때 유저마다 수신되는 광고 메시지는 다를 수 있다. 이 후 [8]카카오모먼트 dsp 플랫폼을 통해 자신이 등록한 광고가 얼마나 많은 반응으로 이어졌는지에 대한 보고서를 확인할 수 있다. - 개발자 관점
광고주가 [1]카카오모먼트 dsp 플랫폼을 통해 [2]광고를 등록한다. 등록된 광고는 [3]소재최적화와 유저타게팅 기능을 수행하는 모델의 입력으로 주어지고 [4]유저ID와 소재ID 리스트가 출력된다. [5]이 리스트를 메시지 발송기에 입력하면 채널 구독자들에게 카톡 광고 메시지가 전송된다. 이후 채널 구독자들은 광고를 무시하거나 클릭하는 반응으로 이어지는데 이를 사용자 반응이라고 하고 그 기록을 사용자 반응 로그라고 한다. 사용자 반응 로그는 [8] 광고 리포트 작성에 활용되고 [6]카프카에 입력된다. [7]카프카에 입력된 사용자 반응 로그(데이터)는 스마트 메세지 시스템의 모델을 재학습하는데 활용된다. 모델의 재학습이 완료되면 기존에 사용하던 모델을 재학습된 모델로 갱신한다.
스마트 메시지 서비스를 설계, 개발하면서 고민한 문제들과 해결 사례
- 쿠버네티스 클러스터 환경에 최적화된 MAS(Micro Service Architecture) 시스템으로 구현하기
- 어떤 언어를 사용할까? -> Go 언어
- WHY?
- MSA의 경우 기능을 기준으로 서버를 분리한다. 즉 하나의 서버 컴퓨터는 하나의 기능을 수행하는 데 기존에 사용하는 Spring은 여러 가지 강력한 기능을 제공하지만 너무 무겁다. 하지만 Go의 경우 하나의 기능만 수행하지만 가볍고 빠르다.
- Go는 필요한 라이브러리만 조합하여 실행 파일을 경량화할 수 있고, 빠른 성능을 보장한다.
- Go는 타 언어에 비해 컴파일 시간이 짧기 때문에 container image 빌드가 빠르고 패키지 의존성 관리가 쉽기 때문에 DockerFile같은 container 설계도를 쉽게 짤 수 있다. 즉 효율적으로 CI/CD를 할 수 있다. (여기서 container란 어떤 실행 파일이 container를 실행할 수 있는 어떤 환경에서도 동일하게 동작하도록하는 경량화된 가상화 기술이다.)
- Go는 언어 자체 난이도가 높지 않고 문법이 단순하여 빠르게 코드를 작성할 수 있고 코드리뷰 또한 수월하다.
- Go는 라이브러리 선택지가 많다(장점이자 단점)
- Spring에서 Go로 전환 효과
- 서버 코드가 60% 감소
- API 서버 기준 pod(container의 묶음) 메모리 사용량이 1/3 수준으로 감소
- WHY?
- 기존 시스템은 서버 간 통신이 HTTP 통신으로 이루어져 있어 민감정보(광고생성/정지/취소)가 유실되거나 중복처리될 가능성이 높고 저장소에 장애에 취약하다.
-> Event-driven Architecture 의 일종인 Kafka기반 Event Sourching Architecture로 전환
- Why?
- Event를 안전하게 저장하여 유실 방지
- Kafka Transaction을 사용하여 서버 처리도중 이슈가 발생하더라도 중복 처리 방지
- CQRS(Command and Query Responsibility Segregation, 명령과 쿼리 분리 )패턴 구현
main DB에 저장된 데이터에 대하여 광고 스케줄링 서버가 담당하는 광고 상태 변경(Command) 기능과 API 서버가 담당하는 조회(Query) 기능을 분리하였다.
- API 서버 개발자와 광고 집행 서버 개발자간 업무 coupling을 없애고 각자 도메인 로직 개발에 집중할 수 있게하여 효율적인 개발이 가능해짐
- 광고 상태 변경(Command) 이벤트 요구사항이 추가되어도 유연하게 확장 가능
- 기존 방식에 비해 광고주가 요청한 광고 상태 변경이 DB에 반영되는 데까지 시간이 더 오래걸린다. 하지만 광고 상태 변경 요청은 지연시간(Latency, 요청을 처리하는 실제 시간을 제외한 이동/대기 시간)보다 정합성이 더 중요한 작업이고 광고 상태 변경 요청 자체의 트래픽이 낮아 Latency에 민감하지 않기 때문에 리스크가 적다.
- Why?
- 광고 스케줄링 서버는 등록된 광고를 적절한 시간에 발송해주는 서버이다. 즉, 등록된 광고를 보고 발송 예정 작업 정보를 생성, 관리(저장), 집행한다. 만약 서버가 예정 작업을 생성하고 관리하는 도중 장애가 발생하는 경우 서버 자체는 Kubernetes 기술을 활용해 새로 실행시킬 수 있다. 하지만 관리하고 있던 예정 작업 정보는 어떻게 될까? 예정 작업 정보를 서버 메모리에 저장한 경우 -> 서버에 장애가 발생하면 정보가 유실되므로 광고가 집행되지 않는다. 예정 작업 정보를 외부 저장공간에 저장한 경우 -> 서버를 하나만 사용하면 문제가 없으나 여러 서버를 띄워 병렬처리 하는 경우 중복 집행을 방지하기 위해 추가적인 로직(락)이 필요해진다.
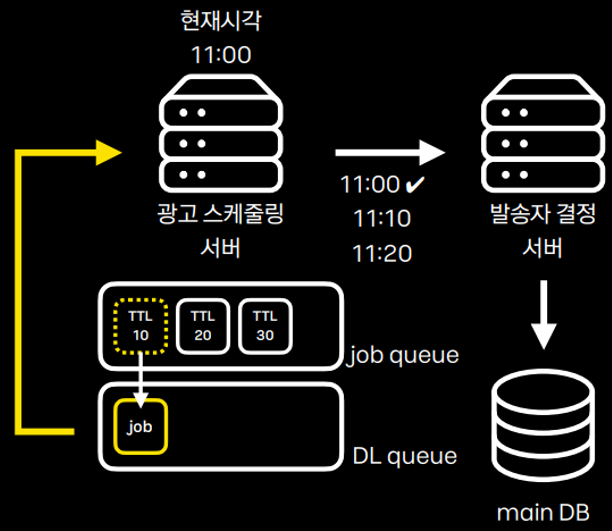
- 위 문제를 해결하기 위해 RabbitMQ 기반 Delay Queue 사용
- Why?
- Delay Queue 사용하면 예정 작업 정보를 서버 외부에 안전하게 저장하면서 스케줄링 자동화를 편리하게 수행할 수 있게 해준다.
- Delay Queue = RabbitMQ의 (Message TTL + Dead Letter Exchanges)
- 기술
- Message TTL : 큐에 넣은 메시지의 유효기간(TTL, Time To Live)을 설정하는 기능 유효기간이 지난 메시지는 DL(Dead Letter)가 되고 DLX(Dead Letter Exchanges)에 의해 DL queue로 이동
- Dead Letter Exchanges : RabbitMQ DLX(Dead Letter Exchange)는 Dead Letter가 된 Massage를 지정된 Exchange에 전송하는 기능
- Delay Queue 사용하면 예정 작업 정보를 서버 외부에 안전하게 저장하면서 스케줄링 자동화를 편리하게 수행할 수 있게 해준다.
- How? ( [그림 4] 참조 )
- job queue에 작업 예정 정보 메시지를 넣는다. 이 때 TTL은 작업이 집행되어야할 시간까지 남은시간 이다. 예를 들어 11시에 집행되는 작업을 10시 50분에 job queue에 넣는 경우 TTL은 10분이된다.
- job queue에서 대기중인 작업 정보 메시지의 유효기간이 지나 Dead Letter가 되면 Dead Letter Exchanges에 의해 DL queue로 이동한다.
- DL queue에 있는 메시지를 현재 실행중이 서버(들 중 하나)가 consume 하여 집행한다.
- Why?
- 위 문제를 해결하기 위해 RabbitMQ 기반 Delay Queue 사용
- 어떤 언어를 사용할까? -> Go 언어
kafka streams 기술 소개 kafka에 대한 기초 지식이 필요할 듯 하다.
- Apache kafka에서 공식적으로 배포하는 도구
- kafka와 연동되어 Stream처리를 할 수 있는 Java 라이브러리
- Java 라이브러리 이므로 Spring을 사용해도 되고 public static void main()으로 시작하는 기본 Java 애플리케이션을 구현해 사용해도 된다.
- kafka consumer가 파티션 단위로 컨슈머 그룹을 만들어 데이터를 처리하는 것과 비슷하게 kafka streams는 파티션 단위로 task를 만들어 데이터를 병렬 처리한다. -> scale out 가능하다
- 상태기반처리(stateful)를 위한 두 가지 도구 rocksDB와 변경로그(changelog) 토픽을 내포하고 있다.
- 로컬에서 상태를 저장하되 상태를 백업하는 용도로 변경로그를 토픽에도 저장하여 안전하고 지속성 있게 데이터를 처리할 수 있다.
이해안됨
- 로컬에서 상태를 저장하되 상태를 백업하는 용도로 변경로그를 토픽에도 저장하여 안전하고 지속성 있게 데이터를 처리할 수 있다.
- kafka streams 사용 방법
- 스트림즈DSL
- 프로세서API
kafka streams 적용 과정
- kafka stremas를 선택한 이유
- 스마트 메세지 시스템에서 스트림 데이터 처리를 위해 고려해야 하는 점
- 카프카(Kafka)와의 호환성 - 스마트 메시지 시스템에서 사용자 반응 로그 데이터(원천 데이터)는 모두 카프카로 모인다. 따라서 원천 데이터를 처리하기 위해서는 카프카와 연동되는 애플리케이션이 필요하다.
- 상태기반처리(Stateful) - 비상태기반처리(Stateless)는 트랜잭션(하나의 광고 메세지)은 서로 독립적(아무 관계도 없고 영향을 미치지 않음)이기 때문에 상태를 고려하여 처리할 필요가 없다. 따라서 상태(state)를 저장할 필요가 없다. 반대로 상태기반처리(Stateful)는 트랜잭션 간 관계가 있거나 영향을 미치기 때문에 상태(state)가 트랜잭션의 처리 순서나 방법에 영향을 미친다. 따라서 상태(state)를 저장하고 상태에 따라 처리해야 한다. 스마트 메세지 시스템의 트랜잭션은 "XX시 OO분에 발송되어야할 광고 메세지" 또는 "XX시 OO분에 수집된 반응 로그" 라는 관계가 있기 때문에 광고 메시지를 발송할 때와 사용자 반응 로그를 취합할 때 상태를 고려한 상태기반처리를 수행해야 한다.
- 운영(Maintenance) - 최초 개발시 뿐만 아니라 지속적으로 운영해야 하기 때문에 운영상의 이점(코드 수정을 위한 프레임워크와 라이브러리의 지속적인 지원, 개발 중 이슈에 대한 트러블슈팅을 위한 개발자 커뮤니티 존재)
- 스마트 메세지 시스템에서 스트림 데이터 처리를 위해 고려해야 하는 점
- 적용 방법
- 유저 데이터 매핑 : Redis에 저장된 사용자 정보와 원천 데이터(사용자 반응 로그)를 매핑하고 mongoDB(main DB)에 저장해야 할 때는 비상태기반처리(stateless)로(독립적으로) 매핑함수를 사용하여 kafka streams 애플리케이션 구현
- 로그 취합 및 저장 : 원천 데이터(사용자 반응 로그)는 초당 1,000건 정도 유입된다.
영상에 나온 설명"어마어마한 양의 원천 데이터를 저희가 사용하는 최종 저장소인 mongoDB에 한 번 호출하면 네트워크 사용량 뿐만아니라 mongoDB에 부하가 극심하게 발생될 수 있습니다. 그래서 스트림즈에서 윈도우 시간으로 데이터 처리를 실행한 뒤 저장하는 방식을 적용하였습니다." ->필자의 해석원천 데이터를 바로 mongoDB(스마트 메세지 시스템의 main DB)에 저장 하면 한 번 호출할 때마다 호출 조건에 맞는 데이터를 한 번에 호출해야 하는데 이를 적절하게 구분할 조건이 없어 어마어마한 양의 데이터(ex 아직 처리하지 않은 데이터)를 호출하게 된다. 때문에 네트워크 사용량과 mongoDB에 부하가 극심하게 발생될 수 있다. 이를 해결하기 위해 실시간으로 들어오는 원천 데이터를 mongoDB에 저장하기 전에 kafka streams 애플리케이션에서 시간을 1분 단위 윈도우들로 구분하고 해당 윈도우에 들어온 데이터에 상태("11:01 분에 들어옴")를 추가하는 데이터 처리를 수행한 후 몽고 DB에 저장하여 나중에 데이터를 호출할 때 상태를 조건으로 호출("11:01 분에 들어온 데이터만 호출해라")하게 하여 네트워크 사용량과 mongoDB에 부하를 줄인다. - 유닛 테스트 - Apache Kafka가 제공하는 TopologyTestDriver를 사용하여 유닛 테스트 자동화 함
정리
하나의 서비스를 개발하는 과정에서 데이터 시스템을 설계 할 때 고민하는 문제들과 해결 사례를 보면서 데이터 엔지니어가 어떤 문제를 풀고 있는 지 알 수 있었다. 중요한 정보가 유실, 중복 처리 되는 것을 예방하기 위해 메시징 시스템을 활용하는 방법(RabbitMQ를 활용한 Delay Queue, kafka 기반 Event sourching architecture를 활용한 CQRT 패턴 구현)과 kafka streams 를 활용한 실시간 상태기반처리, MSA에서 Go언어의 장점들을 알 수 있었다.


