출처 : https://if.kakao.com/2019/program?sessionId=e5695f93-8c50-4be2-b8dd-c275fbcf85df
if(kakao)2021
함께 나아가는 더 나은 세상
if.kakao.com
광고의 시작에서 끝, 그 사이에는 여러 데이터가 있고 광고시스템 내의 서로 다른 시스템간 데이터를 연결하기 위해 우리가 하고 있는 노력, 시행착오 그리고 앞으로 해결해야 할 일들에 대해 소개합니다.
리뷰 포인트
- 카카오 광고 시스템 소개
- 카카오 데이터 시스템 구성 요소(기술 스택)
- 카카오 광고 시스템 데이터 파이프라인
카카오 광고 시스템 소개

- 광고 플랫폼 종류
- SSP(Supply Side Platform) : 어떤 서비스에는 광고를 내보낼 수 있는 공간이 존재한다 예를 들어 카카오 채팅방 목록의 맨 위에는 광고를 위한 공간이 있다. 서비스 개발자가 그 공간에 대한 정보(크기, 트레픽 등)을 SSP에 제공하면 SSP는 DSP에게 어떤 광고를 노출하면 좋을 지 물어본 후 그 공간에 맞는 광고를 반환한다. 그러면 서비스 개발자는 그 광고를 해당 공간에 띄우면 된다. 주 역할은 광고를 띄울 공간을 공급(Supply)하기 위해 사용하는 플랫폼이다.
- DSP(Demand Side Platform) : 광고주 입장에서 자신의 광고를 내보내기 위한 공간을 구매할 수 있는 플랫폼이다. 해당 공간 판매하는 기능 뿐만아니라 DMP의 분석 결과를 바탕으로 광고가 노출되는 공간의 정보(어떤 사용자가 주로 그 공간을 보는 지)를 출력하는 기능, 광고 집행 후 보고서를 제공하는 기능. SSP에게 가장 적합한 광고를 전달하는 기능 등을 포함한다. 주 역할은 광고를 띄우기 위해 공급된 공간을 구매하여 자신의 광고를 내보낼 수 있게 하는 플랫폼이다.
- DMP(Data Management Platform) : 소재최적화 기술, 유저타게팅 기술 등의 데이터 분석 기술을 활용해 가장 효율이 높은 광고 집행을 수행하기 위해 데이터를 분석하고 그 결과를 제공하는 플랫폼이다.
- SSP(Supply Side Platform) : 어떤 서비스에는 광고를 내보낼 수 있는 공간이 존재한다 예를 들어 카카오 채팅방 목록의 맨 위에는 광고를 위한 공간이 있다. 서비스 개발자가 그 공간에 대한 정보(크기, 트레픽 등)을 SSP에 제공하면 SSP는 DSP에게 어떤 광고를 노출하면 좋을 지 물어본 후 그 공간에 맞는 광고를 반환한다. 그러면 서비스 개발자는 그 광고를 해당 공간에 띄우면 된다. 주 역할은 광고를 띄울 공간을 공급(Supply)하기 위해 사용하는 플랫폼이다.
- 광고 시스템 개발/운영에 필요한 직무
- 데이터 분석가
- 담당 역할 : 영업, 기획, 의사결정
- 데이터 과학자
- 담당 역할 : 노출모델개발, 추천모델개발
- 데이터 엔지니어
- 담당 역할 : 개발
- 데이터 분석가
카카오 데이터 시스템 구성 요소(기술 스택)
- 기술 스택
- 유입(Ingestion) + 실시간 처리(Processing/streaming) :
- 수집 대상 서버(ex 광고 공간을 공급하는 서비스를 수행하는 서버)에 Beats 혹은 logstash 기술을 활용해 필요한 데이터를 카카오의 kafka 혹은 play framework로 전송하게 하고
- 유입된 데이터는 play framework + akka 혹은 Flink 기술을 활용해 실시간 처리를 수행한다.
- 일괄 처리(Processing/batch) :
- 하이브(hive)와 임팔라(IMPALA) 기술을 사용해 하둡 HDFS에 있는 데이터를 배치 처리함.(하이브와 임팔라는 하이브 메타스토어를 공유하여 같이 작업할 수 있음)
- 하이브(hive)와 임팔라(IMPALA) 기술을 사용해 하둡 HDFS에 있는 데이터를 배치 처리함.(하이브와 임팔라는 하이브 메타스토어를 공유하여 같이 작업할 수 있음)
- 저장(Stores) :
- 배치처리와 파일 수집은 하둡 HDFS,
- 개별 이벤트 저장은 cassandra,
- OLAP(On-Line Analytical Processing, Business Intelligence를 위해 최종 사용자가 직접 대화식으로 데이터에 접근하고 분석하는 기술)를 위한 데이터 저장은 apache hbase,
- 광고 보고서 데이터 저장은 elasticsearch,
- 캐싱은 redis 를 사용함
- 제공(Serving) :
- 내부적으로 데이터를 확인하기 위해 tableau, zeppelin, apache kylin을 사용하고
- 외부에 데이터를 제공하기 위해 kafka, spring 기반 API 를 사용한다.
- 운영(Operation) :
- 유입되고 있는 이벤트 데이터들을 빠르게 확인하기 위한 kibana
- workflow managing을 위한 Airflow,
- 어플리케이션에서 발생하는 로그를 알람으로 추적하기 위한 Sentry,
- 대쉬보드를 위한 Grafana,
- 지표를 수집하고 보기 위한 Prometheus
- 유입(Ingestion) + 실시간 처리(Processing/streaming) :
- 기술 스택 도입 과정
- 데이터 제공(Serving) 관련 요구사항과 해결방법
- 요구사항 : 데이터를 다각도로 빠르게 분석하면 좋겠어요
- 다양한 조합의 빠른 분석을 할 수 있었으면
- 조회하는 방식이 친숙했으면
- BI 툴과의 연동이 쉬웠으면
- 새로운 조합의 데이터를 쉽게 만들수 있었으면
- 해결방법 : Apache kylin을 적용
- Apache kylin이 지원하는 기능
- 다양한 조합의 빠른 분석을 위한 OLAP Cube
- 친숙한 조회 방식을 위한 SQL
- BI 툴과 쉽게 연동하기 위한 JDBC/ODBC
- 새로운 조합의 데이터를 쉽게 만들기 위한 Cube wizard
- Apache kylin이 지원하는 기능
- 요구사항 : 데이터를 다각도로 빠르게 분석하면 좋겠어요
- 일괄 처리 관련 요구사항과 해결방법
- 요구사항 : 배치 작업의 운영이 쉬웠으면 좋겠어요
- 작업간 의존성을 잘 관리할 수 있었으면
- 재시도/재실행이 쉬웠으면
- 필요한 기능을 손쉽게 추가할 수 있었으면
- 처리 상태를 한눈에 볼 수 있었으면
- 해결방법 : Apache airflow 적용
- Apache airflow가 지원하는 기능
- 작업간 의존성 관리를 위한 Task dependency manage
- 재시도/재실행을 쉽게 하기 위한 Task retry/re-run
- 필요한 기능을 손쉽게 추가하기 위한 Plugin
- 처리 상태를 한눈에 볼 수 있는 Graph/Tree view
- Apache airflow가 지원하는 기능
- 요구사항 : 배치 작업의 운영이 쉬웠으면 좋겠어요
- 데이터 제공(Serving) 관련 요구사항과 해결방법
카카오 광고 시스템 데이터 파이프라인
- OLAP 데이터 파이프라인
- 절차 (그림 2 참조)
- [1] 여러 DB에 저장되어 있는 광고 관련 데이터들과 노출/클릭/전환 등 광고가 집행 될 때 발생한 사용자 반응 데이터들을 특정 라이프 사이클마다 일괄 처리하여 하둡 HDFS에 저장한다.
- [2] kylin 서버는 하둡에 저장된 데이터를 읽어 HBase에 저장하고 Tableau서버에 전송한다.
- [3] Tableau서버는 수신한 데이터를 바탕으로 대쉬보드를 작성하여 출력한다.
- [1] 여러 DB에 저장되어 있는 광고 관련 데이터들과 노출/클릭/전환 등 광고가 집행 될 때 발생한 사용자 반응 데이터들을 특정 라이프 사이클마다 일괄 처리하여 하둡 HDFS에 저장한다.
- 절차 (그림 2 참조)
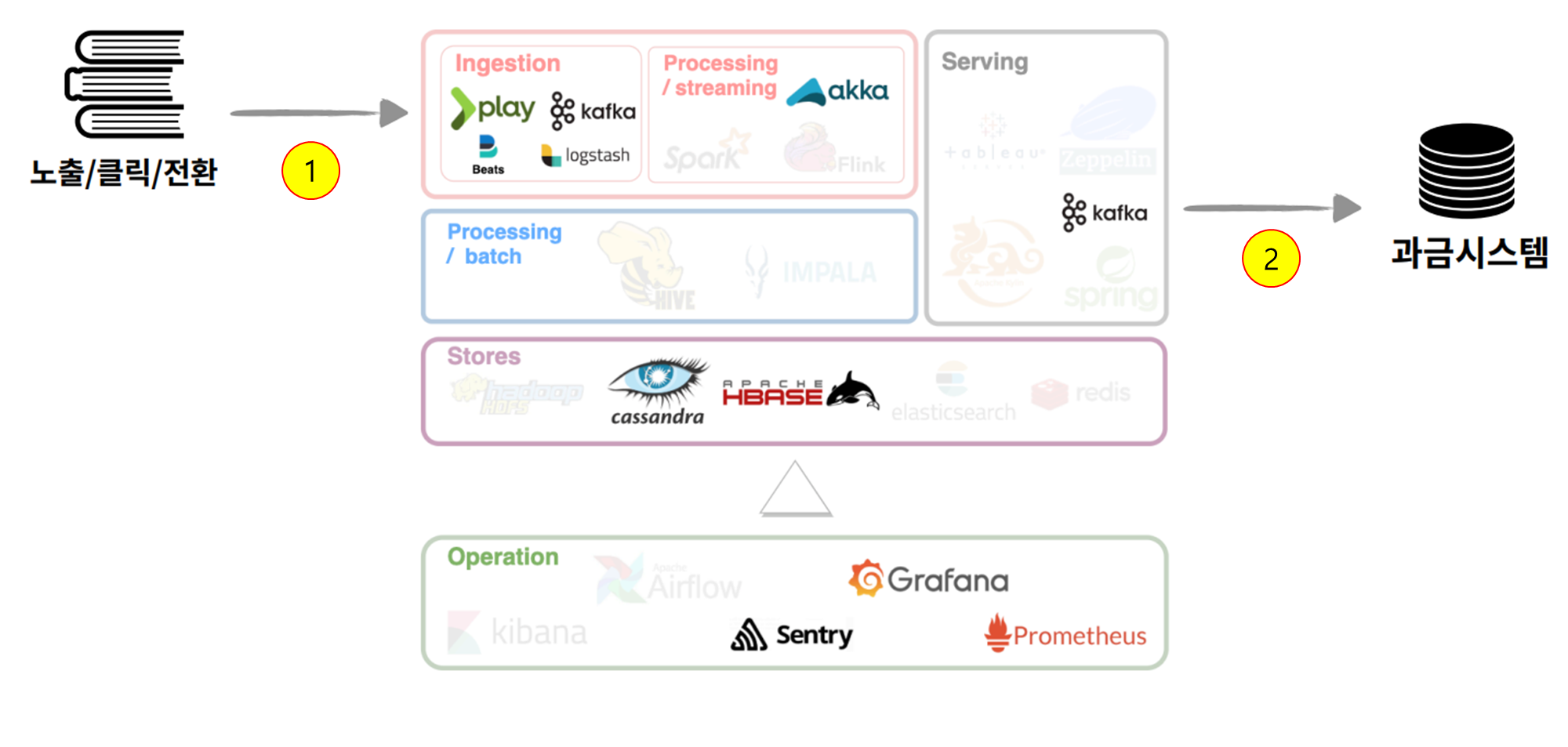
- 이벤트 연결 파이프라인
- 절차 (그림 3 참조)
- [1] 여러 서비스에서 집행 중인 광고가 노출/클릭/전환될 때 발생한 사용자 반응 데이터들 play framework, beats, logstash, kafka를 통해 수집하여 cassandra에 저장하고 서로 연결 시킨다. 연결이란 예를 들어 어떤 광고 A가 서비스 b에서 10번 클릭되고 서비스 c에서 20번 클릭 됐을 때, 데이터 10과 20을 연결하면 광고 A의 총 클릭 수는 30이라는 정보를 얻을 수 있다.
- [2] 연결된 데이터는 kafka를 사용해 과금 시스템으로 전송된다.
- [1] 여러 서비스에서 집행 중인 광고가 노출/클릭/전환될 때 발생한 사용자 반응 데이터들 play framework, beats, logstash, kafka를 통해 수집하여 cassandra에 저장하고 서로 연결 시킨다. 연결이란 예를 들어 어떤 광고 A가 서비스 b에서 10번 클릭되고 서비스 c에서 20번 클릭 됐을 때, 데이터 10과 20을 연결하면 광고 A의 총 클릭 수는 30이라는 정보를 얻을 수 있다.
- 절차 (그림 3 참조)
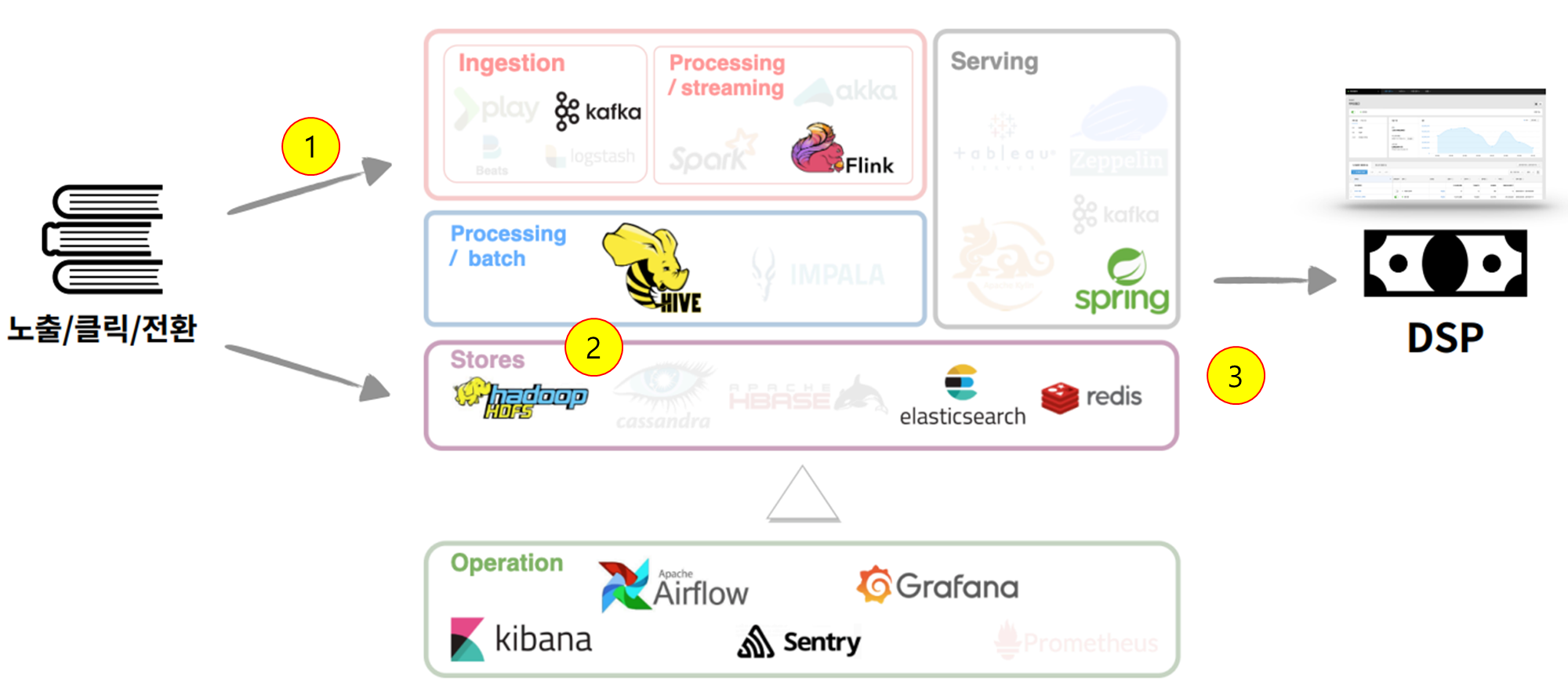
- 보고서 파이프라인
- 절차 (그림 4 참조)
- [1] 실시간 보고서를 만들기 위해 사용자 반응 데이터들을 kafka에서 실시간으로 가져와서 Flink를 통해 실시간 처리 후 elasticsearch에 저장한다.
- [2] 일괄 보고서를 만들기 위해 하루에 한 번 하둡 HDFS에 저장되어 있는 사용자 반응 로그 데이터들을 Hive를 통해 elasticsearch에 저장한다.
- [3] 실시간 보고서와 일괄 보고서를 통합하여 스프링을 통해 DSP로 전달한다. 보고서의 경우 여러 번 조회될 수 있기 때문에 redis를 사용해 캐싱한다.
- [1] 실시간 보고서를 만들기 위해 사용자 반응 데이터들을 kafka에서 실시간으로 가져와서 Flink를 통해 실시간 처리 후 elasticsearch에 저장한다.
- 절차 (그림 4 참조)
- ...
마무리
하나의 서비스서 사용되는 기술 스택들과 파이프라인을 공부할 수 있어서 데이터 엔지니어링에 대해 감을 잡을 수 있었다.


