주요 작업
- 데이터 수집 후 DataWarehouse 에 저장
- 분석 결과 DataWarehouse 에 저장
- 웹 서빙
데이터 수집 작업은 Youtube Data API를 활용해 인기 동영상에 어제까지 달린 댓글을 수집하고 DataLake에 저장하는 작업이다. 자세한 API 활용 방법은 아래 PPT 파일에서 확인할 수 있다.
데이터 분석 작업은 수집된 데이터에 대해 다음과 같은 연산을 수행하고 그 결과를 Data Warehouse에 저장한다. soynlp 라이브러리의 cohension_forward score 기반 문장 -> 토큰(단어)화, 토큰 후처리, 각 토큰의 점수 계산, Word2Vec을 활용한 토큰 to 벡터, 벡터(토큰)간 유사도 계산, t-SNE를 활용한 벡터(토큰)를 2차원 공간으로 변환.
웹 서빙 작업은 분석 결과를 확인 할 수 있는 대시보드 웹 페이지를 작성하여 서빙하는 작업이다.
좋은 데이터 시스템이란?
좋은 데이터 시스템은 신뢰성(reliability), 확장성(scalability), 유지보수성(maintainability)이 높아야 한다. 따라서 시스템 설계 과정에서 어떤 선택을 해야하는 순간이 온다면 위 세 가지 특성을 충분히 고려해야 한다.
- 신뢰성(reliability)
어떤 시스템의 "신뢰성이 높다"는 것은 하드웨어나 소프트웨어 결함, 심지어 인적 오류 같은 역경에 직면하더라도 시스템은 지속적으로 올바르게 동작(원하는 성능 수준에서 정확한 기능을 수행)할 가능성이 높다는 것을 의미한다.
결함이란 장애의 원인이고 장애는 올바르게 동작하지 못하고 시스템 전체가 멈춘 경우를 의미한다. 신뢰성이 높은 시스템을 구축하기 위해서는 장애가 발생하지 않을 확률 즉, 시스템이 정상 동작할 확률을 높여야 한다.- 소프트웨어 결함
- 내결함성이 뛰어난 소프트웨어를 개발한다
- 시스템의 상호작용에 대해 주의 깊게 생각하기
- 빈틈없는 테스트
- 프로세스 격리 : 소유하지 않은 메모리 공간에 액세스하지 못하도록 서로 다른 소프트웨어 프로세스를 분리하는 것 - container 기술을 활용한 가상화
- 죽은 프로세스 재시작 허용
- 내결함성이 뛰어난 소프트웨어를 개발한다
- 인적 오류 대응
- 오류의 가능성을 최소화하는 방향으로 시스템 설계
- 사람이 가장 많이 실수하는 장소(부분)에서 사람의 실수로 장애가 발생할 수 있는 부분을 분리하라. 실제 데이터를 사용해 안전하게 살펴보고 실험할 수 있지만 실제 사용자에게는 영향이 없는 비 프로덕션 샌드박스를 제공
- 장애 발생의 영향을 최소화하기 위해 인적 오류를 빠르고 쉽게 복구할 수 있게 하라
- 성능 지표와 오류율 같은 상세하고 명확한 모니터링 대책을 마련
- 신뢰성(reliability)을 높이기 위해 필요한 것
- 하드웨어 중복(redundancy) 추가
- 프로세스 격리
- 죽은 프로세스 재시작 허용
- 모니터링 대책 마련
- 테스트 코드 작성
- 소프트웨어 결함
 한국_지역_인기_동영상_댓글_수집_및_통계.py
0.01MB
한국_지역_인기_동영상_댓글_수집_및_통계.py
0.01MB
 댓글_분석.py
0.01MB
댓글_분석.py
0.01MB
- 확장성(scalability)
어떤 시스템의 "확장성이 높다"는 것은 시스템의 데이터 양, 트래픽 양, 복잡도가 증가하면 이를 처리할 수 있는 적절한 방법이 있어야 한다는 것을 의미한다.
확장성 있는 시스템을 구축하기 위해서는 주요 동작과 잘 하지 않는 동작이 무엇인지, 각 동작 별로 부하가 얼마나 발생할지, 목표하는 성능은 어느정도 인지알아야 하며, 이를 바탕으로 애플리케이션에 적합한 확장성을 갖춘 아키텍처를 설계해야 한다.
시스템에서 수행되는 모든 작업은 적은 연산으로 이루어지는 것이 좋으나 그것이 불가능한 경우 요청이 많은 작업일 수록 간단한 연산으로 구현하는 것이 좋다.- 부하 측정
부하 측정은 윈도우10 환경의 Local에서 수행되었다. [그림 1]에 나오는 수집 작업은 Youtube API.pptx 를 참조해 api key를 복사한 후 한국_지역_인기_동영상_댓글_수집_및_통계.py에 Line 15를 수정하고 실행하면 부하를 측정할 수 있다. [그림 2]에 나오는 분석 작업은 수집 작업을 완료하고 나온 csv 파일을 가지고 댓글_분석.py을 실행하면 부하를 측정할 수 있다.- 데이터 수집 부하
수집 대상은 지난 일 주일 간 한국 지역 인기동영상 200개에 달린 모든 댓글이다. [그림 1]을 보면 약 34만개의 댓글을 수집하였고 사용되는 메모리는 271.7 MiB이고 총 수행 시간은 80분이다. 맨 처음에 인기동영상 200개를 질의하는 코드가 있으므로 N개의 Worker를 만들고 각 Worker는 queue에 저장된 인기 동영상 ID를 가져가 수집하게 하면 동시성문제 없이 병렬처리가 가능할 것이다. - 데이터 분석 부하
[그림 2]를 보면 사용된 메모리는 1223.4Mib이고 총 수행시간은 102분이다. 분석 작업은 명확한 의존관계가 있다. 수집 작업 -> 토큰화 -> 랭킹 -> 벡터화 -> TSNE 순서로 작업이 진행되어야 한다. - 웹 서빙 부하
DataWarehouse에서 분석된 데이터를 가져와서 출력하는 작업을 수행하게 될 것이다. 분석 데이터는 날짜별로 저장되고 검색되기 때문에 시계열 데이터베이스로 저장하고, 최근 날짜를 더 많이 검색해볼 것으로 예상되기 때문에 캐싱을 추가하면 더 빠른 서비스가 가능할 것이다.
- 데이터 수집 부하
- 확장성(scalability)을 높이기 위해 필요한 것
- 캐싱 + cache hit을 metric으로 모니터링
- 병렬 처리
- 시계열 데이터베이스
- 부하 측정
- 유지보수성(maintainability)
어떤 시스템의 "유지보수성이 높다"는 것은 시간이 지남에 따라 여러 다양한 사람들이 시스템 상에서 작업할 것이기 때문에 모든 사용자가 시스템 상에서 생산적으로 작업할 수 있어야 할 수 있어야 한다는 것을 의미한다.
- 유지보수작업 예시
- 버그 수정
- 시스템 운영 유지
- 장애 조사
- 새로운 플랫폼 적용
- 새 사용 사례를 위한 변경
- 기술 채무 상환
- 새로운 기술 추가
- ...
- 유지보수성이 높은 시스템 설계 원칙
- 운용성(operability) : 운영팀이 시스템을 원활하게 운영할 수 있게 쉽게 만들어라
- 운영 중 일부 측면은 자동화할 수 있고 또 자동화해야 한다.
- 좋은 모니터링으로 런타임 동작과 시스템의 내부에 대한 가시성 제공
- 개별 장비 의존성 회피, 유지보수를 위해 장비를 내리더라도 시스템 전체에 영향을 주지 않고 계속해서 운영 가능해야 함
- 좋은 문서와 이해하기 쉬운 운영 모델 제공
- 적절하게 자기 회복(self-healing)이 가능할 뿐 아니라 필요에 따라 관리자가 시스템 상태를 수동으로 제어할 수 있게 함
- 단순성(simplicity) : 시스템에서 복잡도를 최대한 제거해 새로운 엔지니어가 시스템을 이해하기 쉽게 만들어라
- 추상화 뒤에 복잡한 세부구현을 숨겨라
- 의존성을 줄여라
- 일관성 있는 명명과 용어를 사용
- 발전성(evolvability) : 엔지니어가 이후에 시스템을 쉽게 변경할 수 있게 하라. 그래야 요구사항 변경 같은 예기치 않은 사용 사례를 적용하기가 쉽다. (= 민첩성, 유연성, 수정 가능성, 적응성)
- TDD(Test Driven Development)
- 애자일
- 운용성(operability) : 운영팀이 시스템을 원활하게 운영할 수 있게 쉽게 만들어라
- 유지보수작업 예시
- 유지보수성(maintainability)을 높이기 위해 필요한 것
- CI/CD 자동화
- 테스트 코드
- 모니터링 제공
- 자동 장애 복구
- 로깅
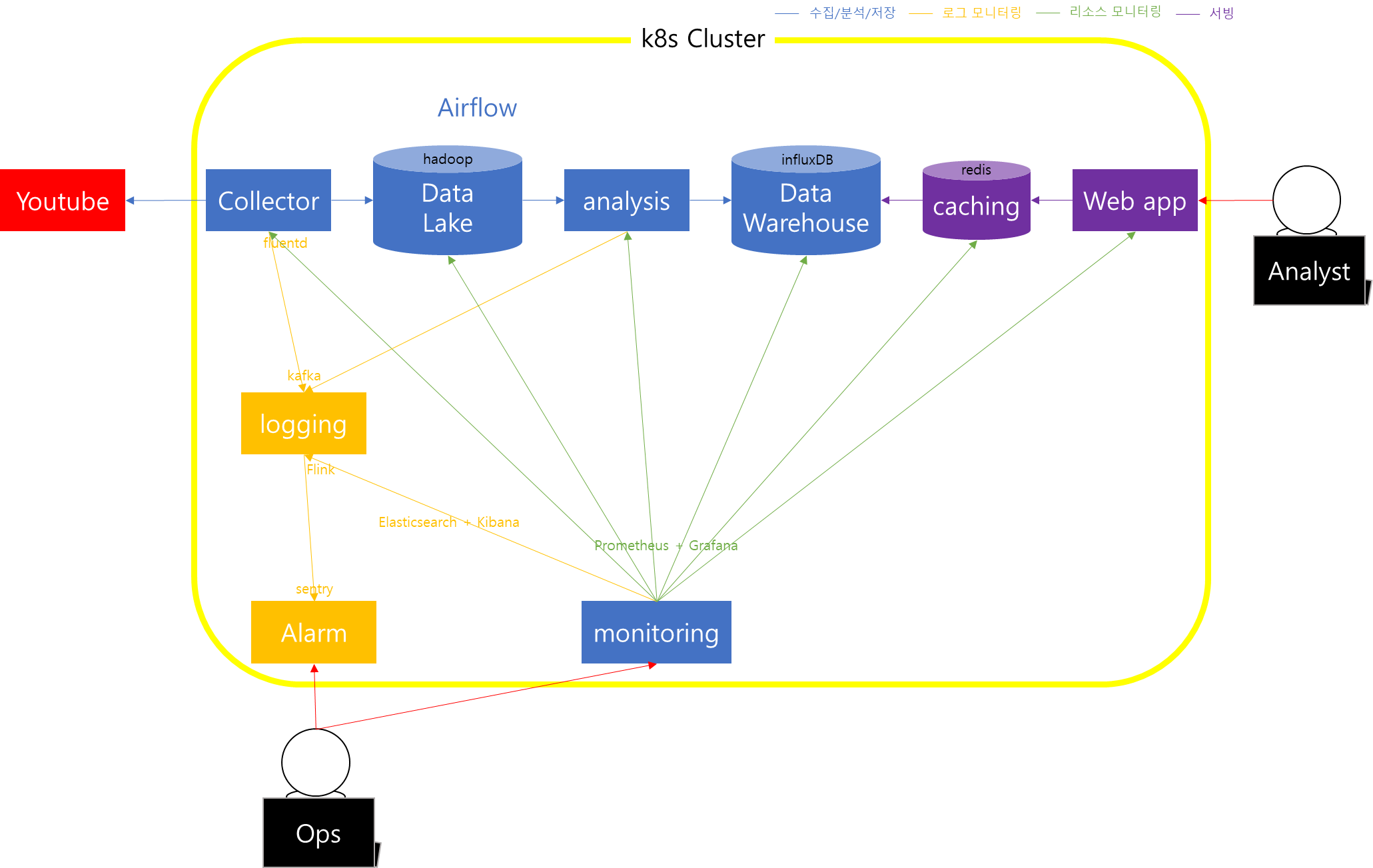
데이터 시스템 설계
- 요구 사항
- youtube 댓글을 수집하고 DataLake에 저장, 병렬로 처리 가능했으면 좋겠다.
- DataLake에 저장된 댓글을 분석하여 Data Warehouse에 저장
- 배포/장애복구 자동화
- workflow 관리
- workflow 처리결과, 에러 등 로깅하고 장애가 많이 발생하는 경우 알람
- workflow 성능및 로그 모니터링
- TDD
- Data Warehouse에 저장된 분석 데이터를 빠르게 읽어서 WebApp을 통해 출력
- 캐싱 + cache hit 모니터링
- 시계열 데이터베이스
- 기술 스택
- container orchestration
- Kubernetes를 활용해 배포/장애복구 자동화
- workflow 관리
- Apache airflow를 사용해 workflow 관리
- 데이터 수집
- google api client를 활용해 유튜브 댓글 수집
- 수집된 데이터를 DataLake에 저장.
- kubernetes의 replicaset과 RabbitMQ 사용하여 병렬 처리함
- Data Lake
- 댓글을 수집하여 Hadoop에 여러 파일로 저장
- Data warehouse
- DataLake에 수집된 데이터를 읽어서 분석 후 결과를 다시 influxDB에 저장
- 캐싱
- redis를 사용해 캐싱
- 리소스 모니터링
- Prometheus를 사용해 kubernetes 리소스의 metric 정보수집 후 grafana를 활용해 대쉬보드화
- 로그 모니터링
- 수집, 분석 과정에서 발생하는 로그를 fluentd를 사용해 Kafka에 produce
- kafka에 수집된 로그는 Flink를 사용해 실시간으로 ElasticSearch에 저장 후 Kibana를 통해 대쉬보드화
- Sentry를 사용해 에러 로그 알람
- container orchestration
'Data Engineering > Youtube Comment Analysis' 카테고리의 다른 글
| [데이터 시스템 구축기] 3. Airflow를 활용한 유튜브 댓글 수집 아키텍처 개선 (0) | 2022.07.08 |
|---|---|
| [데이터 시스템 구축기] 2. Data Warehouse 구축 (0) | 2022.06.22 |
| [데이터 시스템 구축기] 0. 데이터 시스템 구축기란? (0) | 2022.05.24 |


